Deterministic vs Non-Deterministic Systems: Why Predictability Fails
A practical guide to determinism, non-determinism, reproducibility, race conditions, machine learning, distributed systems, and when builders should allow uncertainty.
The bug report usually arrives with one sentence that sounds impossible: "same input, different result."
The test passed yesterday. The model trained twice with the same data and produced slightly different weights. The payment retry created two records instead of one. The agent picked a different tool path on replay. The weather simulation diverged after a small change that looked too tiny to matter.
These are not all the same failure. Some are genuine randomness. Some are race conditions. Some are deterministic systems that are too sensitive to predict in practice. Some are models doing exactly what they were designed to do: sample from uncertainty.
The important distinction is not whether a system feels predictable. It is whether the next state is fully determined by the current state, the inputs, and the recorded context.
The short version
A deterministic system gives the same output when you replay the same initial state and inputs. A non-deterministic system can take different valid paths unless you also capture the source of variation: random seeds, thread interleavings, external timing, model sampling parameters, network retries, hardware behavior, or environmental state.
Good engineering does not mean eliminating non-determinism everywhere. It means knowing where unpredictability creates value, where it creates risk, and what evidence you need to replay the decision later.
Determinism is a contract, not a mood
A pure function is deterministic because it has no hidden state. A compiler can be deterministic if the same source, toolchain, flags, environment, and dependency graph produce the same artifact. A workflow engine can be deterministic if replay emits the same sequence of commands from the same history.
That last condition matters. "Same input" is often an incomplete description. If the code reads the clock, asks an LLM, queries a database, starts two concurrent tasks, or samples from a pseudo-random generator, then the observable input is not the whole input.
The professional version of determinism is replayability: can we reconstruct enough state to explain what happened?
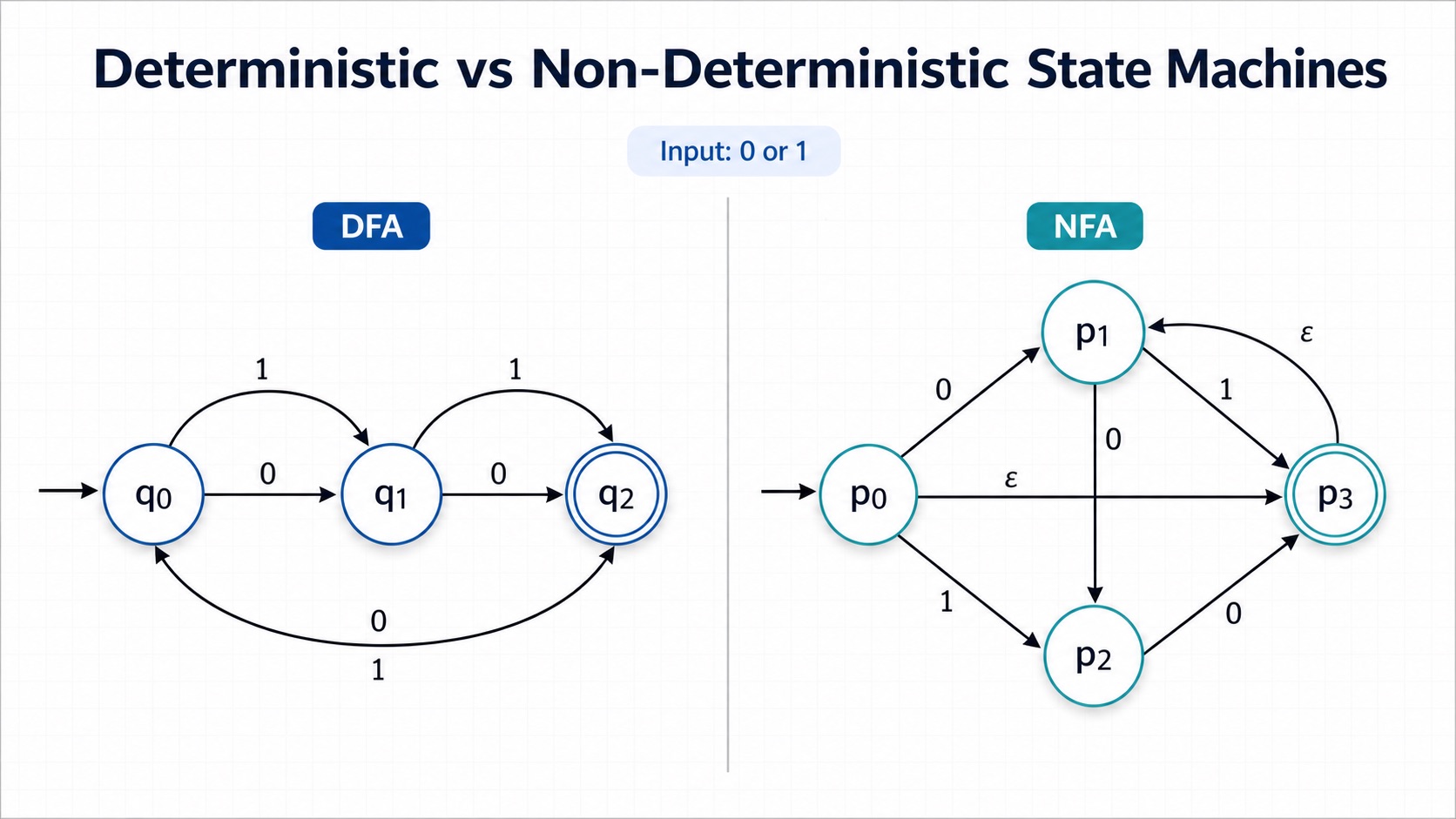 In formal state machines, determinism is about the transition relation: one state/input pair maps to one next state. Production systems add messier hidden inputs such as time, concurrency, and external services.
In formal state machines, determinism is about the transition relation: one state/input pair maps to one next state. Production systems add messier hidden inputs such as time, concurrency, and external services.
Non-determinism is not automatically sloppy
Non-determinism can be intentional and useful.
Machine learning training often uses random initialization, data shuffling, dropout, augmentation, and stochastic optimization. That noise can improve generalization because the model is not trained against one brittle path through the data. Generative AI uses sampling because deterministic decoding would make the system narrower and more repetitive.
Randomized algorithms can avoid adversarial worst cases or simplify a design. Distributed systems use retries because networks fail, and retries are often the practical way to drive a workflow toward completion.
The mistake is not using uncertainty. The mistake is using uncertainty without a control plane.
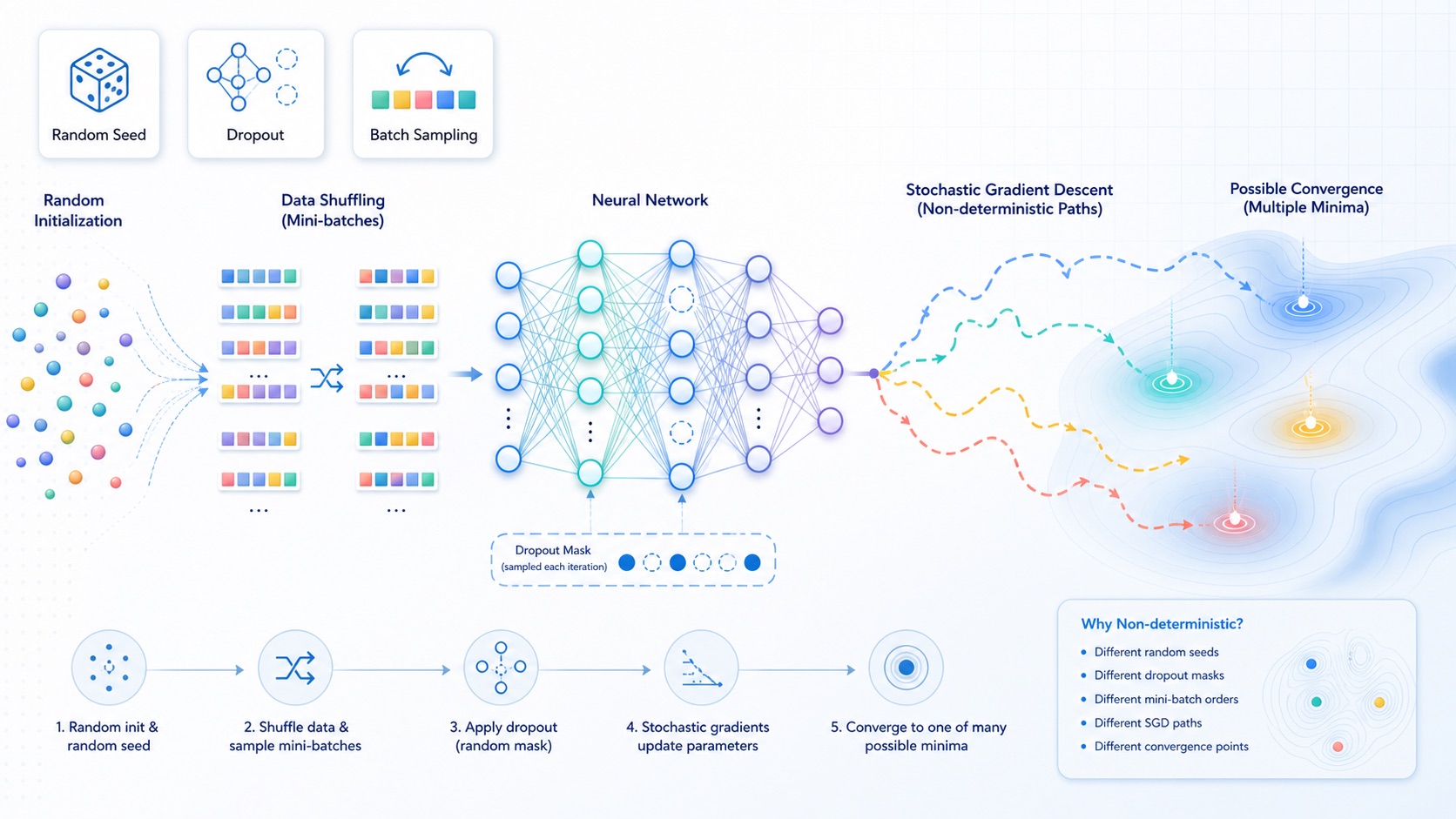 Neural network training can vary because of initialization, batch order, dropout masks, stochastic optimizers, hardware kernels, and framework-level implementation choices.
Neural network training can vary because of initialization, batch order, dropout masks, stochastic optimizers, hardware kernels, and framework-level implementation choices.
The trap: deterministic can still be unpredictable
Chaos theory is the uncomfortable middle ground. A system can be deterministic and still become practically unpredictable because small differences in initial conditions grow rapidly.
Weather is the classic example. Lorenz's 1963 work on deterministic nonperiodic flow showed how a simple deterministic model could produce unstable, nonperiodic behavior. The lesson for builders is not "everything is random." It is sharper: deterministic rules do not guarantee long-range predictability when the system is nonlinear and the initial state cannot be measured perfectly.
Software has its own version of this. A tiny scheduling change exposes a race. A small floating-point difference sends a numerical simulation down another path. A prompt edit shifts an LLM's distribution enough that downstream tool choices diverge. The code may be deterministic inside a narrower boundary, but the operating system, hardware, model runtime, or external world has widened the boundary.
 The butterfly effect is not magic randomness. It is a reminder that deterministic systems can become practically unpredictable when tiny state differences are amplified.
The butterfly effect is not magic randomness. It is a reminder that deterministic systems can become practically unpredictable when tiny state differences are amplified.
Where determinism should be the default
Core business logic should usually be deterministic. Pricing, authorization, ledger movement, permissions, workflow state transitions, audit trails, billing decisions, and compliance checks need predictable behavior because they create obligations.
If a customer is charged, a user is denied access, a shipment is marked complete, or a medical device changes treatment mode, the team must be able to explain why. "The system sampled a different path" is not an acceptable post-incident answer.
This is why serious systems push randomness and external effects to the edge. The deterministic core decides what is allowed. The edge can call providers, sample models, retry network calls, or run experiments, but those effects should be bounded, logged, idempotent, and replayable.
Where non-determinism earns its keep
Use controlled non-determinism when it creates a measurable advantage:
- Model training that benefits from stochastic optimization, dropout, and shuffled data.
- Generative workflows where variety is part of the product.
- Randomized algorithms that improve expected performance or reduce adversarial inputs.
- Simulations that represent uncertainty with distributions instead of false precision.
- Distributed operations where retries improve resilience, as long as side effects are idempotent.
- Exploration systems such as recommendation, search ranking, or reinforcement learning, where the system must learn from alternatives.
The word "controlled" is doing the work. Seeds, sampling parameters, model versions, prompts, tool outputs, request IDs, and environment metadata need to be captured when the result matters.
Where non-determinism becomes production debt
Uncontrolled non-determinism has a distinct smell. The team cannot reproduce a failure, so they rerun the test. The pipeline flakes, so people click rerun until it passes. The model changes behavior after a dependency update, but nobody knows which kernel, seed, or data order changed. A retry appears safe until it duplicates a side effect.
Race conditions are the sharpest version. They are not "random" in a mathematical sense. They are timing-dependent behavior caused by concurrent access to shared state. That makes them hard to reproduce and dangerous in security-sensitive code, because an attacker may be able to widen the timing window or repeat the attempt until the bad interleaving appears.
The right response is not hope. It is synchronization, idempotency, event histories, deterministic replay, stronger tests, and better observability.
The hybrid architecture that usually wins
The most reliable systems do not pick a religious side. They create a deterministic spine and explicit stochastic edges.
For a workflow system, that might mean deterministic orchestration with external calls moved into activities. For a payment flow, it means idempotency keys around retries. For an AI product, it means deterministic authorization and data access, plus model calls that log prompt, model version, temperature, retrieved context, tool calls, and output. For a simulation, it means storing the model version, parameters, random seed, input snapshot, and environment.
The pattern is simple:
- Keep invariants deterministic.
- Isolate uncertainty behind clear interfaces.
- Record enough context to replay or explain decisions.
- Test deterministic paths with exact assertions.
- Test stochastic paths statistically and with property-based checks.
- Make side effects idempotent before adding retries.
- Treat unreproducible failures as observability failures, not mysteries.
A practical decision framework
Prefer determinism when the system controls money, access, safety, compliance, identity, audit records, irreversible state, or customer trust.
Allow controlled non-determinism when the system is exploring, ranking, optimizing, simulating, generating, learning, or dealing with unreliable networks.
Use both when the product needs intelligence without losing accountability. That is the common case now. AI systems, distributed systems, and modern data platforms all need the same basic shape: deterministic guarantees around the things that must never drift, controlled uncertainty around the things that benefit from search or adaptation.
The question every builder should ask
Do not ask only, "Is this deterministic?"
Ask:
- If this produces a surprising result, can we replay it?
- If this retries, can it duplicate a side effect?
- If this samples, did we record the seed, parameters, model, and context?
- If this runs concurrently, what shared state can change between check and use?
- If this is safety-critical, what behavior is bounded by design rather than by luck?
- If this is an AI system, which decisions are allowed to vary and which must be invariant?
Predictability is not a binary property. It is an engineering budget. Spend it deliberately.
The systems that age well are not the ones that pretend uncertainty does not exist. They are the ones that make uncertainty observable, bounded, and accountable.
Source notes
- Python's
randomdocumentation describes the Mersenne Twister core as deterministic and unsuitable for cryptographic purposes, while also documenting seed-based reproducibility limits. - NIST SP 800-90A Rev. 1 specifies deterministic random bit generator mechanisms, which is useful framing for the distinction between entropy sources and deterministic expansion.
- PyTorch's reproducibility guidance notes that full reproducibility is not guaranteed across releases, platforms, or CPU/GPU executions, even when seeds are controlled.
- The JMLR dropout paper explains dropout as randomly dropping units during training to reduce overfitting.
- Edward Lorenz's "Deterministic Nonperiodic Flow" is the classic reference for deterministic systems that produce unstable, nonperiodic behavior.
- MITRE CWE-362 documents race conditions as concurrent access to shared resources without proper synchronization.
- Nancy Leveson and Clark Turner's Therac-25 investigation remains a core safety case study for software-controlled systems, inadequate interlocks, poor error handling, and race-condition risk.
- Temporal's workflow documentation is a practical modern example of deterministic replay requirements in distributed workflow code.
- AWS Builders' Library on idempotent APIs explains why retries need idempotent operation design to avoid duplicate side effects.